
在過去的概念裡,資料中心僅是存放企業伺服器與數位資料的機房,然而隨著雲端運算和 AI 的興起,今日的超大規模資料中心(Hyperscale Data Center)已儼然成為一座算力工廠,透過集結大量的處理器及其算力(以 GPU、TPU 等特定運算處理器為主,關於 xPU 介紹可參考<AI 趨勢下「運算卸載」會帶來哪些 ASIC 與 xPU 的發展?>研究報告),為訓練複雜的 AI 大型語言模型(LLM)提供源源不絕的動力。
而這樣龐大的算力工廠不僅由伺服器構成而已(關於伺服器組成,可參考<雲端服務商機!白話文解構「伺服器產業」>研究報告),在這之中,交換器更是支撐數據傳輸的重要角色,其功能就像是城市中的十字路口交通指揮中心,負責讀取每個數據封包的目的地地址,然後精準地將其轉發到正確的伺服器或下一個交換器,確保數據能夠快速和準確到達目的地。
隨著 AI 相關應用對於資料中心內部資料高流量、高速傳輸的需求增加,交換器及光收發模組相關零組件規格也迎來大幅升級空間,以下是本篇文章重要觀點:
- 資料中心改用脊葉式架構,以滿足 AI 運算對極致低延遲的嚴苛要求
- AI 應用激增的頻寬需求,成為光通訊傳輸規格從 400G 持續邁向 1.6T 的主要催化劑
- 以光代電,已不再是選項,而是資料中心追求傳輸速度下唯一出路
- 高速光收發模組的性能極限與成本結構,正日漸由數位訊號處理器所定義
- 未來光通訊產業在 CPO 技術的引進下將持續革新,供應鏈極具成長潛力
立即開戶 ➠ 富果 App 串接元富證券,研究到下單一站到位!

資料中心改用脊葉式架構,以滿足 AI 運算對極致低延遲的嚴苛要求
在資料中心內,伺服器透過網路線連接到交換器,交換器之間再相互連接,構成一個龐大的內部網路。傳統企業應用中,資料流動以「南北向」(North-South Traffic)為主,使用者從外部網路連線到資料中心內的伺服器,伺服器運算處理過後再回傳資料,多數會採用一種稱為三層式架構(3-Tier Architecture)的設計,這種樹狀結構由下至上分為三層:
- 存取層(Access Layer):位於最底層,由大量的邊緣交換器(Edge Switch)組成,伺服器直接連接到這一層的交換器,通常以 ToR(Top of Rack)交換器形式存在。
- 匯聚層(Aggregation / Distribution Layer):位於中間層,負責將來自多個存取層交換器的流量匯集起來,進行路由管理。
- 核心層(Core Layer):位於最頂層,由少量高性能的核心交換器組成,是整個網路的骨幹,負責在不同匯聚層之間進行高速數據交換 。
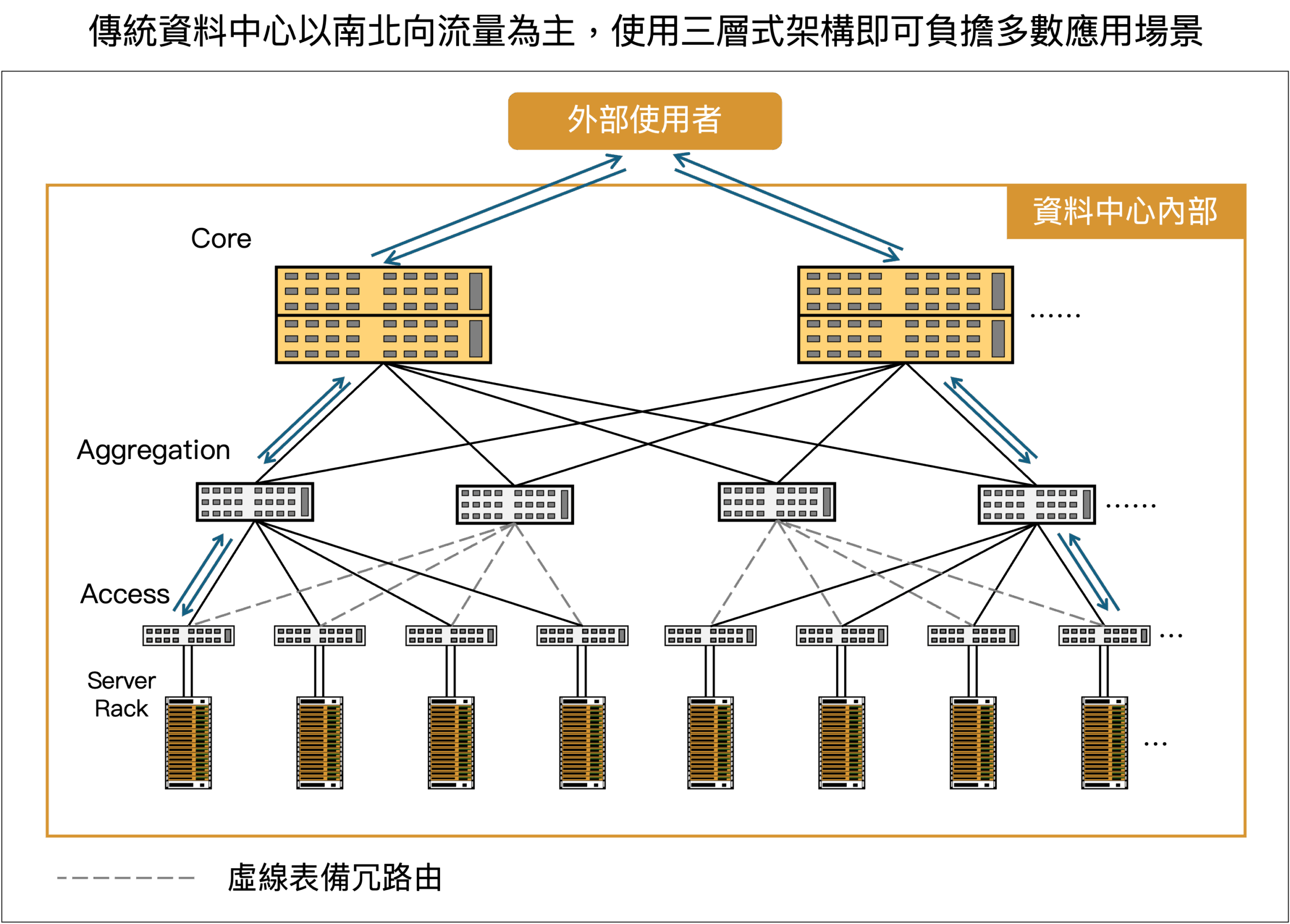
Source:富果研究部
…
閱讀進度


